
Working with ANNIS has been a new experience for me, as I haven’t closely worked with corpus searches before. The interface was a bit overwhelming and confusing at first, but with some visual instructions it was easier to navigate the corpus.
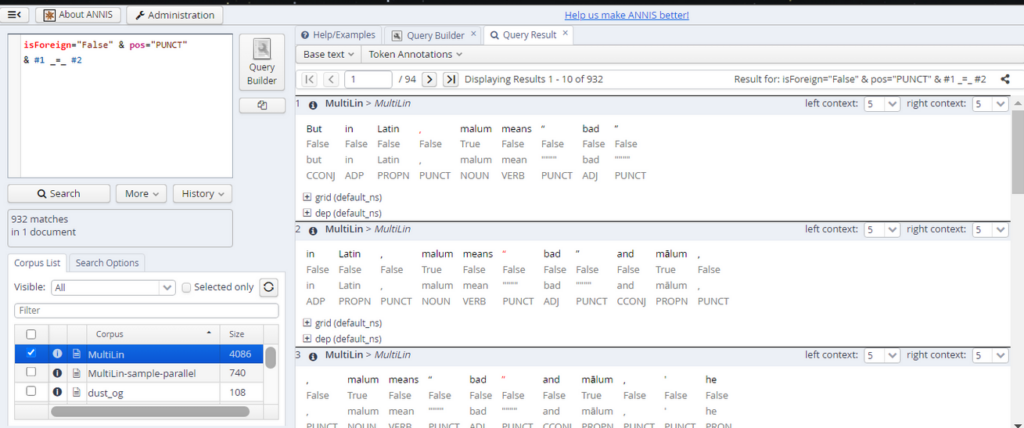
From our previous work on sentence annotation, I was already expecting a high number of Proper Nouns for non-English words, but it was still surprising to see how frequent they were.
I created a table to show the frequency of the more frequent POS types for non-English words.
| isForeign=“True“ | 681 | 100% |
| PROPN | 420 | 61,7% |
| NOUN | 168 | 24,7% |
| ADJ | 26 | 3,8% |
| VERB | 25 | 3,7% |
| ADV | 10 | 1,5% |
| ADP | 10 | 1,5% |
| INTJ | 6 | 0,8% |
| other | 16 | 2,3% |
As you can see, PROPN dominate the non-English words with over 60%. The second highest group is NOUN with roughly 25%. However, this doesn’t mean they are correctly tagged, as our previous experience with sentence annotation already taught us. A quick glance at the so-called PROPN is enough to realize that most of theses probably aren’t actual proper nouns. Again, these seem to be arbitrarily assigned. For NOUN, the matches are a mix of correct and incorrect categorizations. Finding a clear pattern is difficult, but often a NOUN is assigned when a DET or ADJ preceded the word. In those cases, the categorization seems mostly correct.
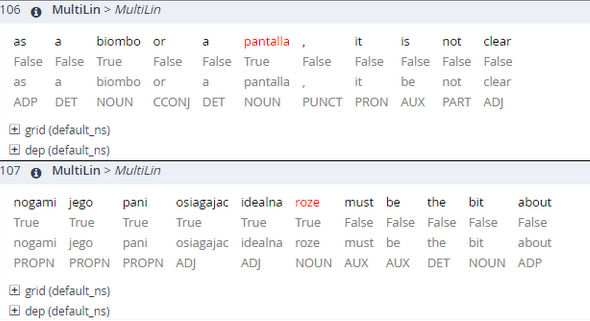
As a comparison, PROPN for English words are less common with about 4%, while NOUN is the most frequent POS type with 12,9%.
| isForeign=“False“ | 3405 | 100% |
| PROPN | 149 | 4,3% |
| NOUN | 438 | 12,9% |
Actually the dominating POS for non-foreign words is punctuation with 932 matches, but that is because every type of punctuation has been marked as non-foreign.
That being said, we are working with a small corpus with many different languages, so it would be too early to draw any generalizing conclusions. Perhaps our own selection of sentences is a little biased, as we do have many sentences that feature nouns from food items or culturally specific terms.
The calculation of the percentages really says a lot! 61.7% non-English proper nouns does not make any sense - particularly not in an English-based language model. A quick Google search reveals that around 37% of English lexemes are nouns, and the number of proper nouns should be significantly smaller. Now, we might argue that our corpus shows such a high percentage because multilingual/postmonolingual literatures have a strong tendency to use proper nouns for its non-English words. However, we found that the proper noun classification is almost always incorrect. The novels we discussed had a tendency to use nouns, but not proper nouns. The 4.3% from your second calculation of the English proper nouns is a much more realistic percentage. Additionally, your observation that within the English words, nouns were the most common POS classification, sheds new light on our observation that the novels we worked with used a high number of non-English nouns. Could it be the case that they do so not only because of the reasons we already discussed in class (culturally specific, grammatically easy to add, untranslatable), but also because nouns are frequent in English anyway?